
The 15th ACM International Conference on Multimedia Retrieval
The 15th ACM International Conference on Multimedia Retrieval
Presenters:
Short Description:
The rapid advancements in large foundation models have significantly transformed the field of visual content generation, impacting domains such as image synthesis, video generation, and 3D modeling. This tutorial will provide an in-depth exploration of the state-of-the-art techniques and methodologies used in visual content generation, emphasizing the role of large-scale generative models. The tutorial will cover fundamental principles, model architectures, recent breakthroughs, and practical applications. We will discuss various generative paradigms, including diffusion models, autoregressive models, and large multimodal models, highlighting their strengths and limitations. Additionally, we will delve into the challenges of controllability, personalization, and realism in generated content, along with open research problems and future directions. By the end of the tutorial, attendees will gain a comprehensive understanding of contemporary visual content generation techniques and their applications, equipping them with the knowledge to leverage these models in their research and projects.
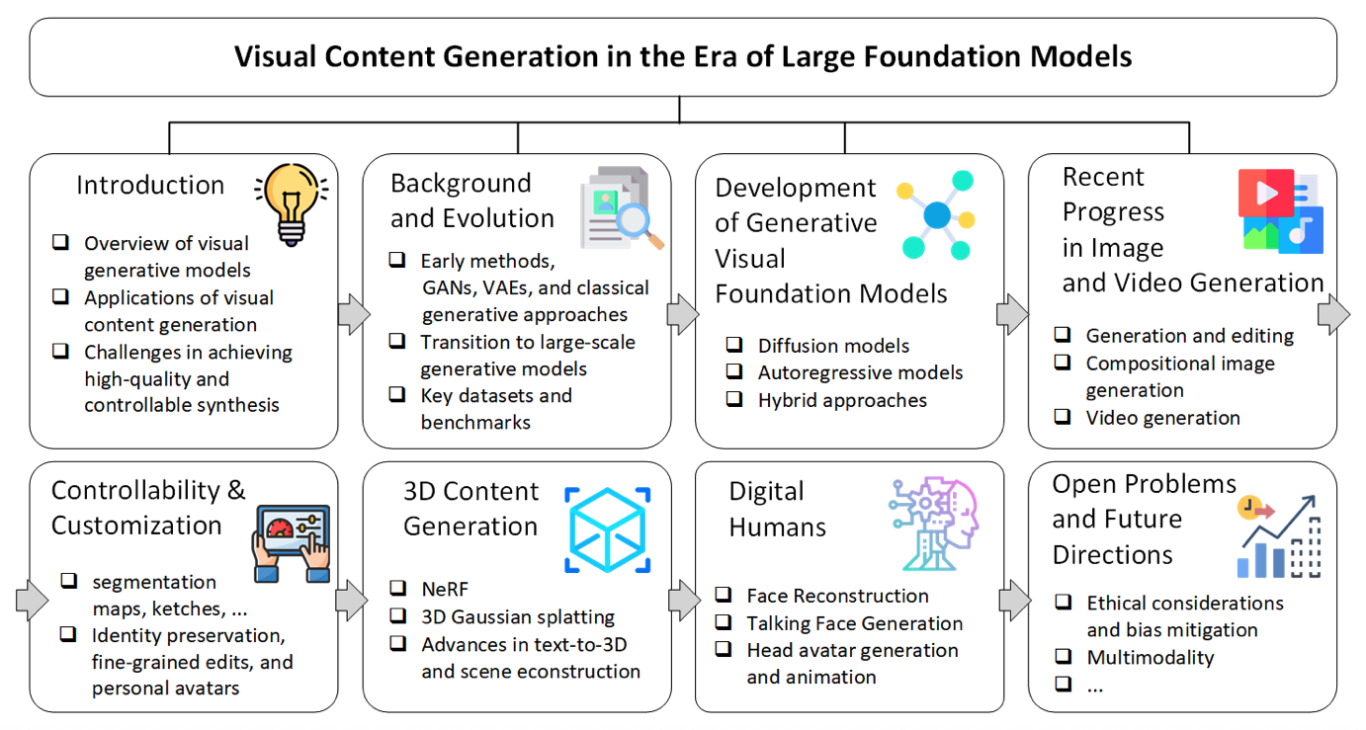
Presenters:
Short Description:
Multimodal Large Language Models (MLLMs), Large Vision-Language Models (LVLMs), and Large Language Models (LLMs) have demonstrated remarkable capabilities across various tasks, including text-based reasoning and multimodal content generation. However, these models frequently generate hallucinations—factually incorrect or misleading content—that pose significant challenges, particularly in high-stakes domains such as healthcare, law, and finance. This tutorial provides a comprehensive exploration of hallucinations in MLLMs, LVLMs, and LLMs, examining their causes, detection methods, and mitigation strategies. We discuss different types of hallucination evaluation and benchmarking and explore state-of-the-art techniques for hallucination mitigation.

We need your consent to load the translations
We use a third-party service to translate the website content that may collect data about your activity. Please review the details in the privacy policy and accept the service to view the translations.